本文共 4716 字,大约阅读时间需要 15 分钟。
只会卖萌的猫主子分分钟变身百兽之王?
白天能不能懂夜的黑?
你的汪星人如果是其他品种会是什么样?
不用想象,有个AI已经(完全不用人插手)“脑补”一切。先展示结果:
给一张小猫咪的图像(左边),AI就能自动让它变身狮子王(右边)。

给一张白天的图像(左边),AI就能自动脑补出夜晚的样子(右边),还把灯效加上了~

给一张冬天的图像(左边),AI就能脑补夏天会是什么景象(右边),还把叶子加上了~

UNIT
上面这些神奇的变身,都属于“图像到图像翻译”的问题。
这些结果都来自Nvidia研究团队的一篇NIPS 2017论文:UNsupervised Image-to-image Translation networks。
Ming-Yu Liu(刘洺堉)等研究员提出了一种基于耦合生成对抗网络(Coupled GAN)和变分自动编码器(VAE)的无监督图像到图像翻译框架,他们还根据首字母缩写(强行)给“无监督图像到图像翻译”起了个名字:UNIT。
论文中提到,从概率模型的角度来分析图像到图像的翻译问题,会发现其中的关键挑战是学习不同领域图像的联合分布。
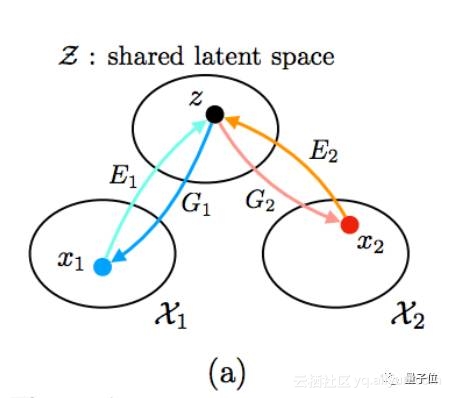
△ 共享潜在空间假设
为了推断联合分布,Ming-Yu Liu等使用了“共享潜在空间假设”,假设不同领域的一对对应图像(x1、x2)可以映射到共享潜在空间(z),UNIT框架就建立在这个假设的基础之上。
上图中的E1和E2是两个编码函数,可以将图像映射到潜在编码,而G1和G2是两个生成函数,从潜在编码映射到图像。
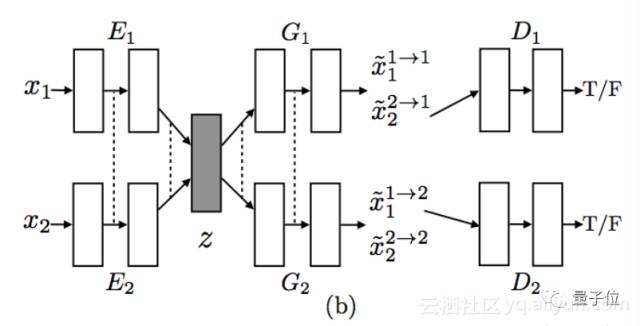
△ UNIT框架结构
在UNIT框架中,研究人员用VAE-GAN对每张图像建模,其中抗性训练目标与权重共享约束相互作用,实施共享空间,以在两个域中生成相对应的图像,而VAE将翻译的图像与相应域中的输入图像关联起来。他们用卷积神经网络(CNN)重建了E1、E2和G1、G2,并通过权重共享限制来实现了共享潜在空间假设。
搞定这个框架之后,研究人员们把它用到了各类无监督图像到图像翻译任务上,比如说……
能完成街景在晴天雨天、白天黑夜、夏景雪景之间的转换,支持640×480的图片;也能在合成图像和真实照片之间进行转换:

还可以在各种狗狗品种之间转换,只要养一只狗,发朋友圈的时候就可以在哈士奇、德牧、柯基、萨摩耶、英国牧羊犬可以变来变去:

除了狗,还有猫,但不是你家的各类长毛短毛主子,而是在家猫、老虎、狮子、美洲狮、美洲虎、猎豹之间互相转换:

当然,最常见的人脸变换这个模型也能搞定,可以生成出金发、微笑、山羊胡、戴眼镜等等特征:

要想说自己的模型好,当然还得和别人的作品比较一下。

几位研究员用街景门牌号数据集SVHN、MNIST和USPS数据集之间的变换测试了模型性能,和SA、DANN、DTN、CoGAN等模型进行了比较。
UNIT框架在SVHN→MNIST任务上的准确率达到0.9053%,远高于同类模型。
Paper+Code
如果你对这篇论文感兴趣,可以直接阅读原文。Paper地址:https://arxiv.org/abs/1703.00848

另外,Nvidia研究团队还放出了这项研究的代码。这是一个无监督图到图翻译的Coupled GAN算法PyTorch实现。
GitHub地址:https://github.com/mingyuliutw/UNIT
更多这个项目的图像变换结果,可以在以下地址查看。
https://photos.app.goo.gl/5x7oIifLh2BVJemb2
我们还挑了几段视频,直接贴在这里。比方冬天变夏天:
还有小猫和兽王互相变身:研究团队
Ming-Yu Liu(刘洺堉)
刘洺堉是Nvidia Research的研究员,专注于计算机视觉和机器学习方向。此前先后供职于英特尔和三菱。刘洺堉2003年在台湾交通大学获得学士学位,2012年在马里兰大学帕克分校获得博士学位。
刘洺堉个人主页的信息显示,今年他已经发布了9篇论文,除了上面这篇中NIPS(Spotlight)之外,他还有一篇论文中了IJCAI,有两篇中了CVPR(包括一篇Oral):
- Tactics of Adversarial Attack on Deep Reinforcement Learning Agents
Paper:https://arxiv.org/abs/1703.06748
Project:http://yclin.me/adversarial_attack_RL
- Deep 360 Pilot: Learning a Deep Agent for Piloting through 360 Sports Videos
Paper:https://arxiv.org/abs/1705.01759
- CASENet: Deep Category-Aware Semantic Edge Detection
Paper:https://arxiv.org/abs/1705.09759
Thomas Breuel
Thomas Breuel是Nvidia的杰出研究科学家(Distinguished Research Scientist)。去年10月加入Nvidia之前,他在Google担任研究科学家的工作。他还长期在德国凯泽斯劳腾大学任教,以及供职于施乐、IBM等公司。
Thomas Breuel本硕毕业于哈佛大学,1992年在麻省理工获得博士学位。来自Google Scholar的信息显示,Thomas Breuel今年除了这篇论文,还有一份专利申请获批。
Jan Kautz
Jan Kautz是Nvidia视觉计算和机器学习研究的高级总监,领导整个视觉计算研发小组。此外他还一直担任伦敦大学学院的教职。
他本科毕业于德国埃尔朗根-纽伦堡大学,随后在滑铁卢大学获得硕士学位,2003年Jan Kautz在德国马克思·普朗克计算机科学研究所获得博士学位。
今年以来,Jan Kautz还发布了十几篇论文,其中包括:
- Learning Affinity via Spatial Propagation Networks
Paper:https://arxiv.org/abs/1710.01020
- Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting
Paper:https://arxiv.org/abs/1708.01670
- A Lightweight Approach for On-The-Fly Reflectance Estimation
Paper:https://arxiv.org/abs/1705.07162
- Mixed-primary Factorization for Dual-frame Computational Displays
Paper:http://research.nvidia.com/publication/2017-06_Mixed-primary-Factorization-for
- Dynamic Facial Analysis: From Bayesian Filtering to Recurrent Neural Network
Paper:http://research.nvidia.com/publication/dynamic-facial-analysis-bayesian-filtering-recurrent-neural-networks
- GA3C: GPU-based A3C for Deep Reinforcement Learning
Paper:https://arxiv.org/abs/1611.06256
Code:https://github.com/NVlabs/GA3C
- Pruning Convolutional Neural Networks for Resource Efficient Transfer Learning
Paper:https://arxiv.org/abs/1611.06440
— 完 —
转载地址:http://fpzeo.baihongyu.com/